
搜索到
7
篇与
的结果
-
 python 调用 OpenStack API OpenStack API 状态码 代码 原因 400 - Bad Request 请求中的某些内容无效。 401 - Unauthorized 用户必须在提出请求之前进行身份验证。 403 - Forbidden 策略不允许当前用户执行此操作。 404 - Not Found 找不到请求的资源。 405 - Method Not Allowed 方法对此端点无效。 413 - Request Entity Too Large 请求大于服务器愿意或能够处理的。 503 - Service Unavailable 服务不可用。这主要是由于服务配置错误导致服务无法成功启动。 Token def get_token(): url = "http://192.168.200.37:35357/v3/auth/tokens" body = { "auth": { "identity": { "methods": ["password"], "password": { "user": { "id": "2b70e2e3e794433a912c15edafa8c5f1", "password": "000000" } } }, "scope": { "project": { "id": "c3694df0e8b748baafcb68b0a92f8b0d" } } } } result = requests.post(url, data=json.dumps(body)).headers['X-Subject-Token'] # print(result) return result User import json import requests url = "http://192.168.100.10:5000/v3/users" body = { "user": { "domain_id": "b64e5c08e1944b5fa6a8725240490aa7", "name": "API-test-user", "description": "API CREATER USER" } } result = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() # print(result) print("user") Image import json import requests from rc import RC def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) def get_images(): url = "http://178.120.2.100:9292/v2.1/images" r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() jprint(r1) def create_image(): url = "http://178.120.2.100:9292/v2.1/images" body = { "container_format": "bare", "disk_format": "qcow2", "name": "api-image", } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1) return r1['id'] def upload_images(): id = create_image() url = "http://178.120.2.100:9292/v2.1/images/" + id + "/file" path_file = "./cirros-0.3.4-x86_64-disk.img" data = open(path_file, 'rb') headers = {"X-Auth-Token": get_token(), 'Content-Type': 'application/octet-stream'} result = requests.put(url, headers=headers, data=data).status_code print(result) upload_images() flavor import json import requests def create_flavor(): url = "http://178.120.2.100:8774/v2.1/flavors" body = { "flavor": { "id": "8848", "name": "api_flavor", "disk": "20", "ram": "1024", "vcpus": "1", } } # r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() print(r1) Network import json import requests def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) def create_net(): url = "http://192.168.200.37:9696/v2.0/networks" # r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() body = { "network": { "name": "api-net", } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() # jprint(r1['network']['id']) jprint(r1) return r1['network']['id'] # net_id = r1['network']['id'] def create_sub(): net_id = create_net() url = "http://192.168.200.37:9696/v2.0/subnets" body = { "subnet": { "name": "api-sub2", "cidr": "172.16.1.0/24", "gateway_ip": "172.16.1.1", "network_id": net_id, "ip_version": 4, } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1) get_token() VM import json import requests def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) url = "http://192.168.200.37:8774/v2.1/servers" body = { "server": { "imageRef": "97d6642f-4cf5-43b6-b505-645b1313fb6e", "flavorRef": "8848", "networks": [{"uuid": "e01e0ce3-4ef2-4b9e-b9e5-74726f351051"}], "name": "api-vm" } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1)
python 调用 OpenStack API OpenStack API 状态码 代码 原因 400 - Bad Request 请求中的某些内容无效。 401 - Unauthorized 用户必须在提出请求之前进行身份验证。 403 - Forbidden 策略不允许当前用户执行此操作。 404 - Not Found 找不到请求的资源。 405 - Method Not Allowed 方法对此端点无效。 413 - Request Entity Too Large 请求大于服务器愿意或能够处理的。 503 - Service Unavailable 服务不可用。这主要是由于服务配置错误导致服务无法成功启动。 Token def get_token(): url = "http://192.168.200.37:35357/v3/auth/tokens" body = { "auth": { "identity": { "methods": ["password"], "password": { "user": { "id": "2b70e2e3e794433a912c15edafa8c5f1", "password": "000000" } } }, "scope": { "project": { "id": "c3694df0e8b748baafcb68b0a92f8b0d" } } } } result = requests.post(url, data=json.dumps(body)).headers['X-Subject-Token'] # print(result) return result User import json import requests url = "http://192.168.100.10:5000/v3/users" body = { "user": { "domain_id": "b64e5c08e1944b5fa6a8725240490aa7", "name": "API-test-user", "description": "API CREATER USER" } } result = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() # print(result) print("user") Image import json import requests from rc import RC def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) def get_images(): url = "http://178.120.2.100:9292/v2.1/images" r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() jprint(r1) def create_image(): url = "http://178.120.2.100:9292/v2.1/images" body = { "container_format": "bare", "disk_format": "qcow2", "name": "api-image", } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1) return r1['id'] def upload_images(): id = create_image() url = "http://178.120.2.100:9292/v2.1/images/" + id + "/file" path_file = "./cirros-0.3.4-x86_64-disk.img" data = open(path_file, 'rb') headers = {"X-Auth-Token": get_token(), 'Content-Type': 'application/octet-stream'} result = requests.put(url, headers=headers, data=data).status_code print(result) upload_images() flavor import json import requests def create_flavor(): url = "http://178.120.2.100:8774/v2.1/flavors" body = { "flavor": { "id": "8848", "name": "api_flavor", "disk": "20", "ram": "1024", "vcpus": "1", } } # r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() print(r1) Network import json import requests def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) def create_net(): url = "http://192.168.200.37:9696/v2.0/networks" # r1 = requests.get(url, headers={"X-Auth-Token": get_token()}).json() body = { "network": { "name": "api-net", } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() # jprint(r1['network']['id']) jprint(r1) return r1['network']['id'] # net_id = r1['network']['id'] def create_sub(): net_id = create_net() url = "http://192.168.200.37:9696/v2.0/subnets" body = { "subnet": { "name": "api-sub2", "cidr": "172.16.1.0/24", "gateway_ip": "172.16.1.1", "network_id": net_id, "ip_version": 4, } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1) get_token() VM import json import requests def jprint(data): print(json.dumps(data, indent=2, sort_keys=True)) url = "http://192.168.200.37:8774/v2.1/servers" body = { "server": { "imageRef": "97d6642f-4cf5-43b6-b505-645b1313fb6e", "flavorRef": "8848", "networks": [{"uuid": "e01e0ce3-4ef2-4b9e-b9e5-74726f351051"}], "name": "api-vm" } } r1 = requests.post(url, headers={"X-Auth-Token": get_token()}, data=json.dumps(body)).json() jprint(r1) -
-
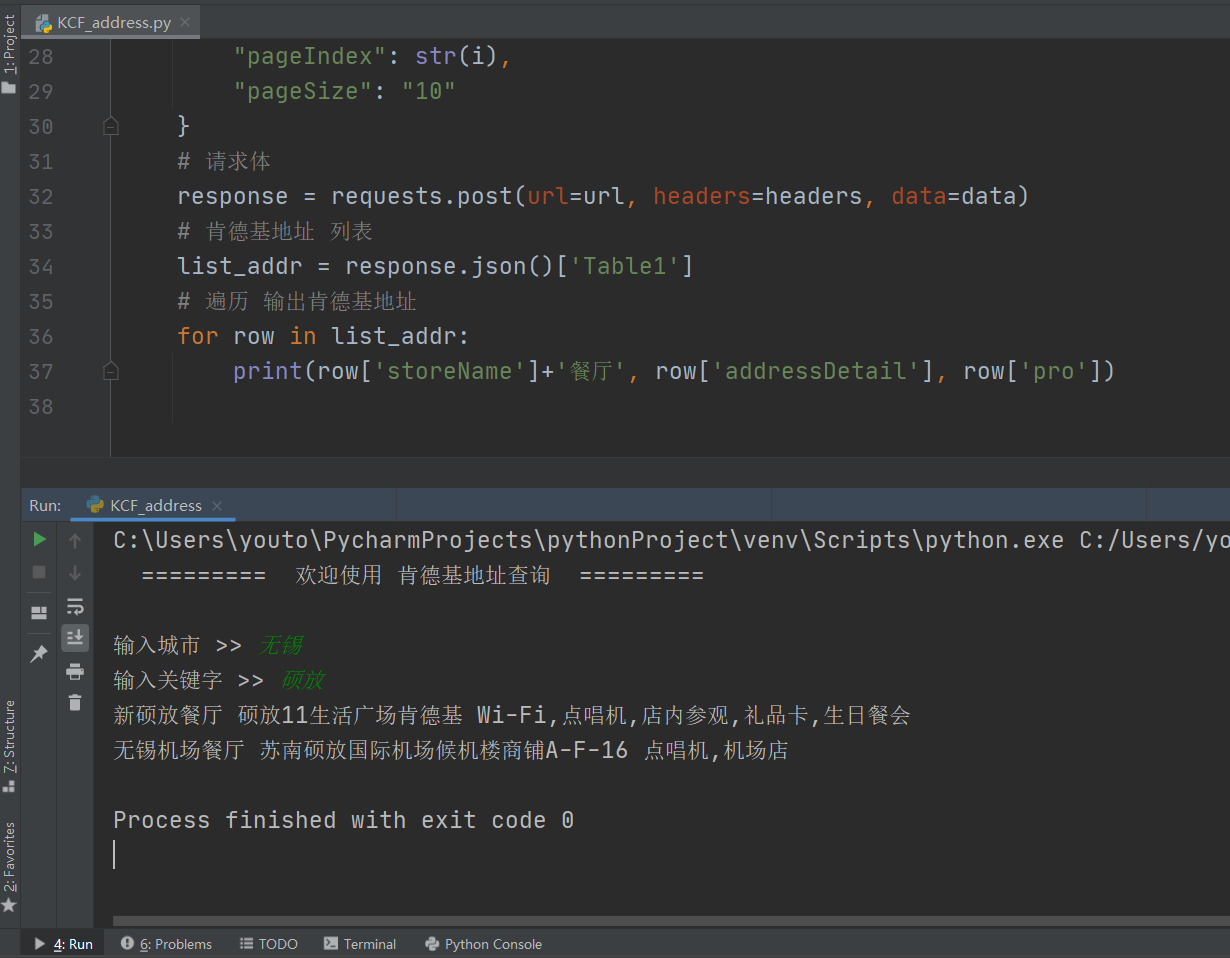
爬取肯德基地址 简单获取肯德基地址 """ 作者:Acha 时间:2021-2-15 功能:查询肯德基地址信息 """ import requests # 肯德基URL url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 提示进入操作界面 print(" ========= 欢迎使用 肯德基地址查询 =========", '\n') # 请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36"} # 城市,关键字 查询 city = str(input("输入城市 >> ")) keyword = str(input("输入关键字 >> ")) # 查询前 5 页地址 for i in range(5): # 动态参数 data = { "cname": city, "pid": '', "keyword": keyword, "pageIndex": str(i), "pageSize": "10" } # 请求体 response = requests.post(url=url, headers=headers, data=data) # 肯德基地址 列表 list_addr = response.json()['Table1'] # 遍历 输出肯德基地址 for row in list_addr: print(row['storeName']+'餐厅', row['addressDetail'], row['pro'])
-
爬取51job岗位信息 提示:岗位链接的xpath表达式会经常变更 # coding=utf-8 """ 时间:2020/11/13 作者:wz 功能:使用python爬虫爬取51job岗位信息 """ import requests from lxml import etree from urllib import parse import time def get_html(url, encoding='utf-8'): """ 获取每一个 URL 的 html 源码 : param url:网址 : param encoding:网页源码编码方式 : return: html 源码 """ # 定义 headers headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Mobile Safari/537.36'} # 调用 requests 依赖包的get方法,请求该网址,返回 response response = requests.get(url, headers=headers) # 设置 response 字符编码 response.encoding = encoding # 返回 response 的文本 return response.text def crawl_each_job_page(job_url): # 定义一个 job dictionary job = {} # 调用 get_html 方法返回具体的html文本 sub_response = get_html(job_url) # 将 html 文本转换成 html sub_html = etree.HTML(sub_response) # 获取薪资和岗位名称 JOB_NAME = sub_html.xpath('//div[@class="j_info"]/div/p/text()') if len(JOB_NAME) > 1: job['SALARY'] = JOB_NAME[1] job['JOB_NAME'] = JOB_NAME[0] else: job['SALARY'] = '##' job['JOB_NAME'] = JOB_NAME[0] # 获取岗位详情 FUNC = sub_html.xpath('//div[@class="m_bre"]/span/text()') job['AMOUNT'] = FUNC[0] job['LOCATION'] = FUNC[1] job['EXPERIENCE'] = FUNC[2] job['EDUCATION'] = FUNC[3] # 获取公司信息 job['COMPANY_NAME'] = sub_html.xpath('//div[@class="info"]/h3/text()')[0].strip() COMPANY_X = sub_html.xpath('//div[@class="info"]/div/span/text()') if len(COMPANY_X) > 2: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = COMPANY_X[1] job['COMPANY_INDUSTRY'] = COMPANY_X[2] else: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = '##' job['COMPANY_INDUSTRY'] = COMPANY_X[1] # 设置来源 job['FROM'] = '51job' # 获取ID job_url = job_url.split('/')[-1] id = job_url.split('.')[0] job['ID'] = id # 获取岗位描述 DESCRIPTION = sub_html.xpath('//div[@class="c_aox"]/article/p/text()') job['DESCRIPTION'] = "".join(DESCRIPTION) # 打印 爬取内容 print(str(job)) # 将爬取的内容写入到文本中 # f = open('D:/51job.json', 'a+', encoding='utf-8') # f.write(str(job)) # f.write('\n') # f.close() # main 函数启动 if __name__ == '__main__': # 输入关键词 key = 'python' # 编码调整 key = parse.quote(parse.quote(key)) # 提示开始 print('start') # 默认访问前3页 for i in range(1, 4): # 初始网页第(i)页 page = 'https://search.51job.com/list/080200,000000,0000,00,9,99,' + str(key) + ',2,' + str(i) + '.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' # 调用 get_html 方法返回第 i 页的html文本 response = get_html(page) # 使用 lxml 依赖包将文本转换成 html html = etree.HTML(response) # 获取每个岗位的连接列表 sub_urls = html.xpath('//div[@class="list"]/a/@href') # 判断 sub_urls 的长度 if len(sub_urls) == 0: continue # for 循环 sub_urls 每个岗位地址连接 for sub_url in sub_urls: # 调用 crawl_each_job_page 方法,解析每个岗位 crawl_each_job_page(sub_url) # 睡 3 秒 time.sleep(3) # 提示结束 print('end.')
-